人工智能
vim
wpf
hbase
csdn云IDE
题集
信号维度
全文检索
rtmp
逻辑运算
猿创征文
mysql存储过程
火鹰优化算法
condition
智能路由器
图搜索算法
keras
QScintilla
普林斯顿大学
赋值运算符
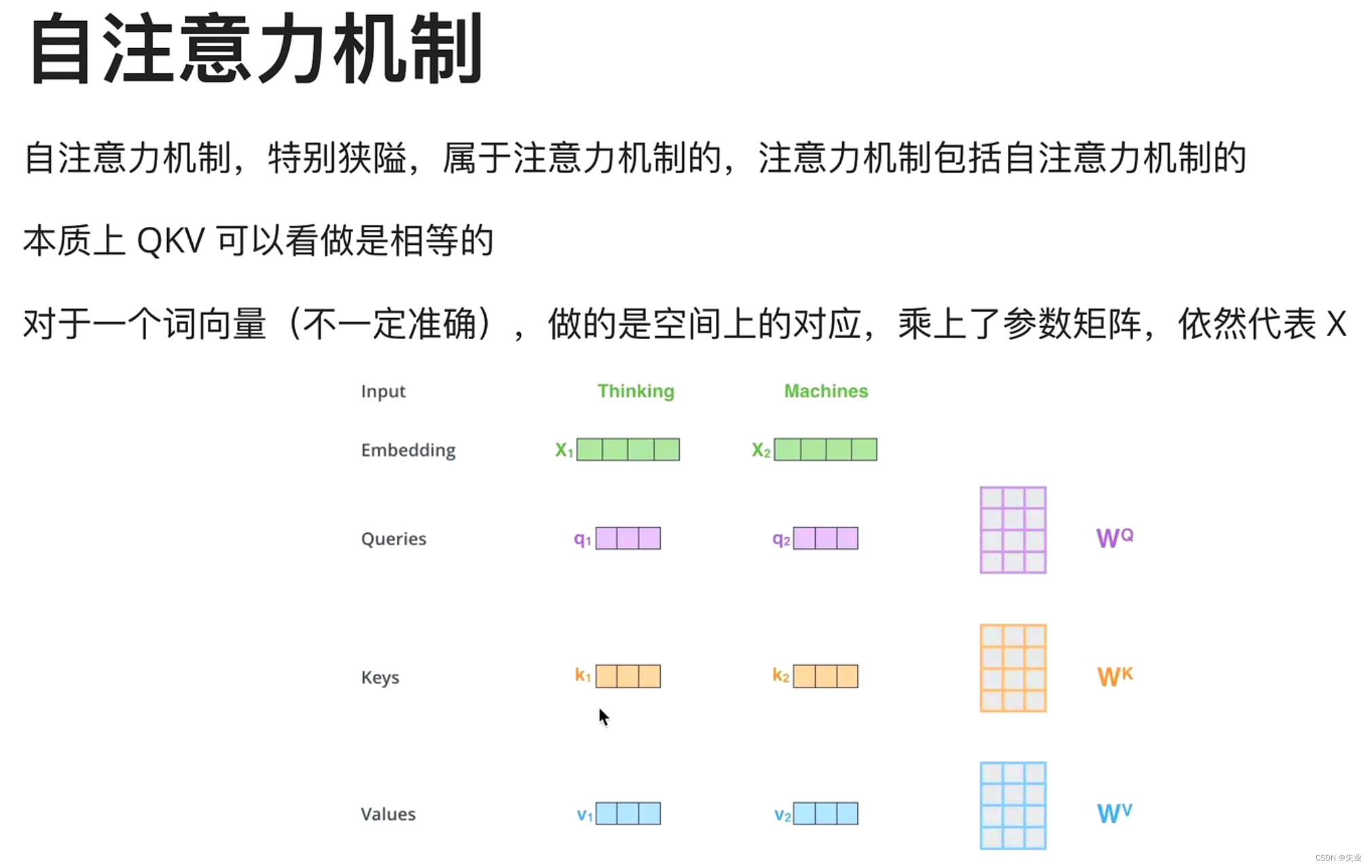
自注意力机制
2024/4/13 17:24:01
分类预测 | Matlab实现KOA-CNN-LSTM-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-LSTM-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-LSTM-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Mat…

多维时序 | MATLAB实现BiTCN-selfAttention自注意力机制结合双向时间卷积神经网络多变量时间序列预测
多维时序 | MATLAB实现BiTCN-selfAttention自注意力机制结合双向时间卷积神经网络多变量时间序列预测 目录 多维时序 | MATLAB实现BiTCN-selfAttention自注意力机制结合双向时间卷积神经网络多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.M…

分类预测 | Matlab实现KOA-CNN-BiLSTM-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-BiLSTM-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-BiLSTM-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1…

transformer的学习记录【完整代码+详细注释】(系列二)
文章目录1 编码器部分实现1.1 掩码张量1.1.1 用 np.triu 生产上三角矩阵1.1.2 生成掩码张量的代码1.1.3 掩码张量可视化展示1.1.4 掩码张量学习总结1.2 注意力机制1.2.1 注意力机制 vs 自注意力机制1.2.2 注意力机制代码解读1.2.3 masked_fill 函数介绍1.2.3 注意力机制的实现代…
NLP(1)--NLP基础与自注意力机制
目录
一、词向量
1、概述
2、向量表示
二、词向量离散表示
1、one-hot
2、Bag of words
3、TF-IDF表示
4、Bi-gram和N-gram
三、词向量分布式表示
1、Skip-Gram表示
2、CBOW表示
四、RNN
五、Seq2Seq 六、自注意力机制
1、注意力机制和自注意力机制
2、单个输出…

简要介绍 | 深度学习中的自注意力机制:原理与挑战
注1:本文系“简要介绍”系列之一,仅从概念上对深度学习中的自注意力机制进行非常简要的介绍,不适合用于深入和详细的了解。 注2:"简要介绍"系列的所有创作均使用了AIGC工具辅助 深度学习中的自注意力机制:原…

多维时序 | MATLAB实现TCN-selfAttention自注意力机制结合时间卷积神经网络多变量时间序列预测
多维时序 | MATLAB实现TCN-selfAttention自注意力机制结合时间卷积神经网络多变量时间序列预测 目录 多维时序 | MATLAB实现TCN-selfAttention自注意力机制结合时间卷积神经网络多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现TCN-s…

论文学习——PixelSNAIL:An Improved Autoregressive Geenrative Model
文章目录 引言论文翻译Abstract问题 Introduction第一部分问题 第二部分问题 Model Architecture网络结构第一部分问题第二部分问题 Experiments实验问题 Conclusion结论问题 总结参考 引言
这篇文章,是《PixelSNAIL:An Improved Autoregressive Geenrative Model》…
NLP(2)--Transformer
目录
一、Transformer概述
二、输入和输出
三、Encoder
四、Decoder
五、正则化处理
六、对于结构的改进?
七、AT vs NAT
八、Cross-attention 一、Transformer概述 Transformer模型发表于2017年Google团队的Attention is All you need这篇论文,…

【自注意力机制必学】BERT类预训练语言模型(含Python实例)
BERT类预训练语言模型 文章目录 BERT类预训练语言模型1. BERT简介1.1 BERT简介及特点1.2 传统方法和预训练方法1.3 BERT的性质 2. BERT结构2.1 输入层以及位置编码2.2 Transformer编码器层2.3 前馈神经网络层2.4 残差连接层2.5 输出层 3. BERT类模型简要笔记4. 代码工程实践 1.…
transformer的学习记录【完整代码+详细注释】(系列七)
文章目录1 模型基本测试运行——copy任务2 介绍优化器和损失函数2.1 优化器和损失函数的代码2.2 介绍 标签平滑函数2.2.1 理论知识2.2.2 具体的参数以及代码展示2.3 训练和预测第一节:transformer的架构介绍 输入部分的实现 链接:https://editor.csdn.n…

分类预测 | Matlab实现KOA-CNN-BiGRU-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-BiGRU-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-BiGRU-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1.M…

分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matla…
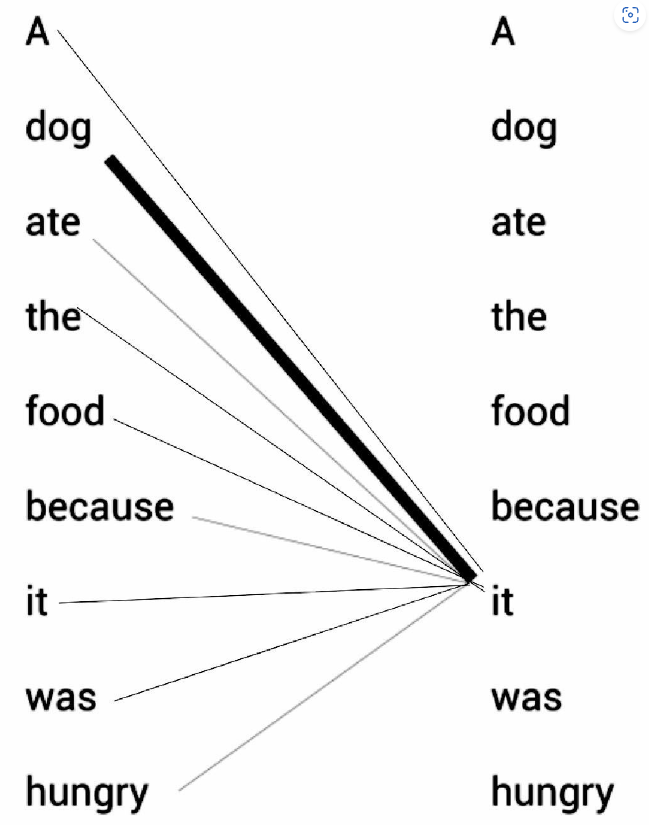
机器学习笔记 - 通过一个例子来快速理解自注意力机制/缩放点积注意力机制
一、一个简单的示例 请看下面的例句:A dog ate the food because it was hungry(一只狗吃了食物,因为它很饿) 例句中的代词it(它)可以指代dog(狗)或者food(食物)。当读这段文字的时候,我们自然而然地认为it指代的是dog,而不是food。但是当计算机模型在面对这两种选…

深度学习(5)---自注意力机制
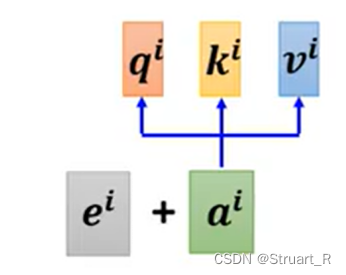
文章目录 1. 输入与输出2. Self-attention2.1 介绍2.2 运作过程2.3 矩阵相乘理解运作过程 3. 位置编码4. Truncated Self-attention4.1 概述4.2 和CNN对比4.3 和RNN对比 1. 输入与输出 1. 一般情况下在简单模型中我们输入一个向量,输出结果可能是一个数值或者一个类…
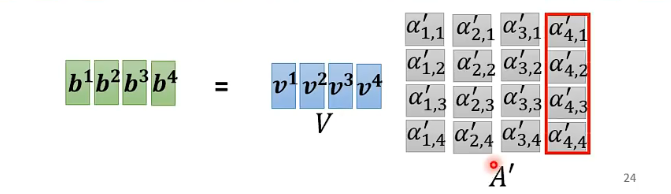
神经网络 || 注意力机制的算法图示和推导
文章目录1 注意力机制是什么?2 多输入怎么处理?3 self-attention的图示4 自己整理一下self-attention的算法过程1 注意力机制是什么?
注意力模型,最近几年在深度学习各个领域都有应用。注意力机制是深度学习常用的一个小技巧&…